Browser reloaded (1/3)
Sauro Torrregiani will jedes F1 Fahrzeug seit 1950 zeichnen. OK, er ist dran, und ich folge ihm dabei. Ich weiß nicht warum, aber das war bei mir ein "Trigger" - ich wollte von jedem Fahrzeug eines Teams Fotos haben, von jedem Fahrer, von seinen Fahrzeugen, von jedem Rennen. Das mit den Fotos hat etwas Zeit beansprucht, der URLDownloader war beschäftigt, und das Taggen aus der Datenbank heraus und manuell bei einzelnen Bildern dauerte seine Zeit. All das Taggen und Indizieren dient aber nur dazu, aus den Fotos (ca. 70.0000 Stück) geeignet selektieren zu können - nach Fahrer, Team, oder Wagen. Das wird mit Lucene und einem Index auf dem kunstvoll erstellten Dateinamen bewerkstelligt. Nun muss man die Auswahl aber auch geeignet durchblättern und anschauen können, das nannte man mal "Foto/Bild/jpg-Browser" bevor "Browser"" die Bezeichnung für einen WWW-Client wurde.
1992: browse
Und auch hier gibt es einen Brückenschlag in die frühen 90iger Jahre ... Bevor wir uns am RUS mit gopher oder WWW beschäftigt haben, habe ich einen Browser für VT100 Terminale geschrieben, mit dem man den ftp Server duchbrowsen konnt. Man konnte mit den Pfeiltaten von Datei zu Datei scrollen, wählte eine Datei aus, konnte einen Infotext zur Datei lesen, in die Datei reinschauen und mit einer Taste herunterladen. Es war so etwas wie der Finder unter MacOS, oder der Windows Explorer für MS-Windows, mit Download Funktion.
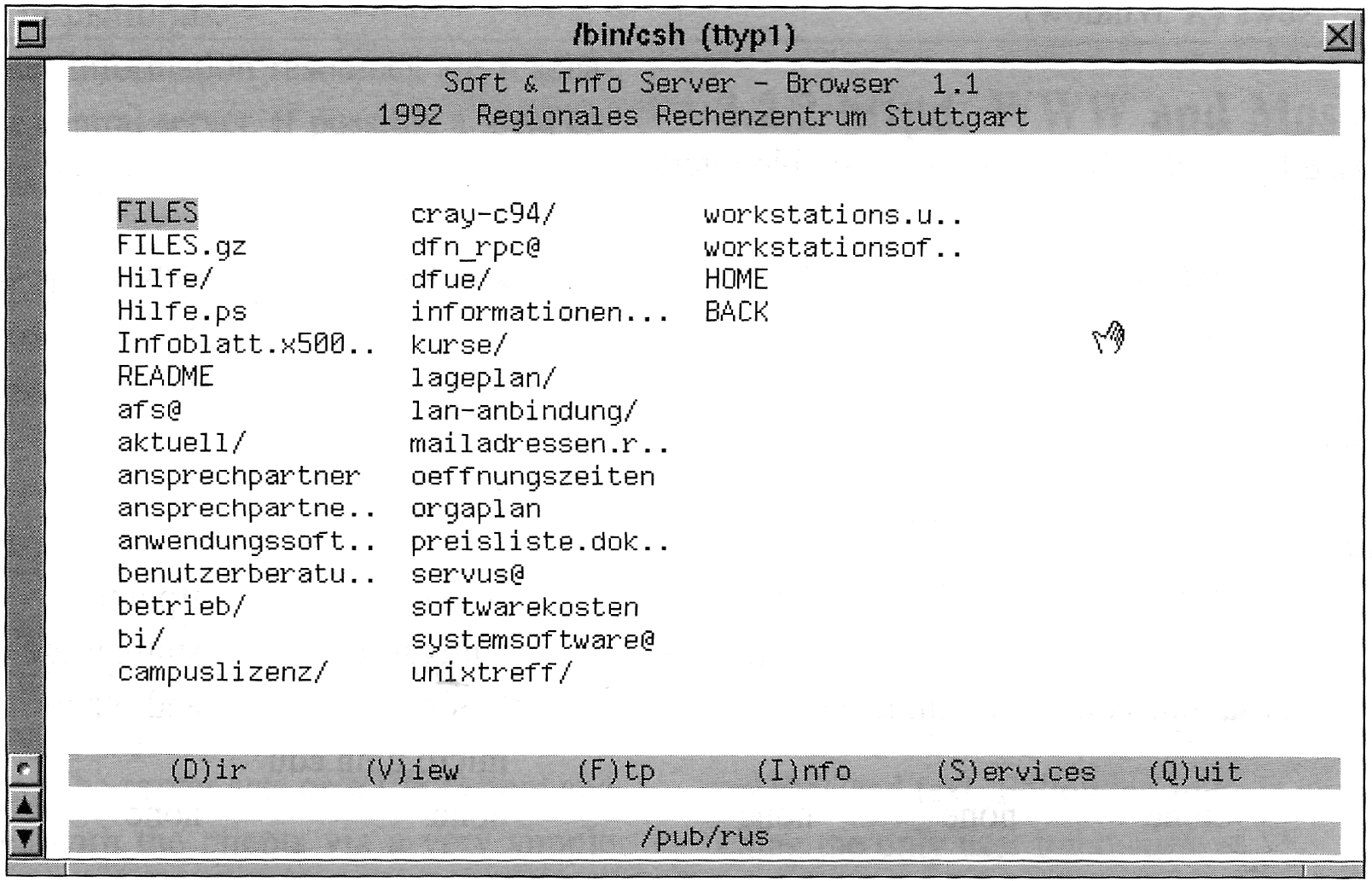
Das Programm hatte seine Anwender, und ich bin auch rückblickend doch zufrieden mit dem was ich da entwickelt hatte. Das Programm war in C unter UNIX geschrieben und verwendete die C-Library "Curses". Curses ist eine Terminalsteuerungsbibliothek für Unix-Systeme, die die Erstellung von Text-Benutzeroberflächen-Anwendungen (TUI) ermöglicht. Der Name ist ein Wortspiel mit dem Begriff "Cursor-Optimierung". Es ist eine Bibliothek von Funktionen, die die Anzeige einer Anwendung auf Zeichenzellen-Terminals (z. B. VT100) verwalten. Als ich 1991 am RUS anfing, war das noch die Norm, und so habe ich auch die Anforderungslage verstanden. Das änderte sich alsbald, Multimedia, WWW, Mosaic, Netscape, *.jpg und *.mpg kamen kurz danach auf. Und da war ich zum erstenmal mit der Erfahrung konfontiert, das eine Antwort (=Software) auf Fragen der Vergangenheit (=Anforderung) oft schnell überholt ist.
Was will ich von einem jpg-Browser?
Beim Entwicklen von dem jpg-Browser stellten sich mir die beiden sich bedingenden Fragen der Software Entwicklung :
Als Informatiker ist man schnell dabei einem "Anforderer" oder "Fachbereich" die intellektuelle Unfähigkeit oder fehlenden Willen zur präzisen Formulierung von Anforderungen zu attestieren. Wenn die Anforderungen die ureigenen, bekannten Abläufe und Prozesse betrifft, ist das vielleicht sogar gerechtfertigt. Anders verhält es sich mit "neuen", noch unbekannten Anforderungen. Das schrittweise, iterative (= agile) Herantasten an ein fachliches Konzept, inklusive einer "eingebauten" Irrtumsfähigkeit ist da die einzig probate Vorgehensweise. Mir war anfangs nicht klar, was genau ich da bauen wollte. Visuelle Konzepte sind außerdem schwer vorhersehbar was die Wirkung auf den Betrachter angeht. Der Vorgang der Anforderungsklärung mit mir selber war inkrementell, erratisch, iterativ und langwierig.
Rückblickend habe ich mir dabei eine Reihe von Fragen beantwortet, die ich vorab nicht hätte beantworten können - ich kannte die Fragen gar nicht.Mengen: Mit was für Daten habe ich es hier zu tun?
Das Was? (=Anforderung) hängt doch auch von den Eigenschaften der Bildern(=Daten) ab die man darstellen möchte. Bei dem darzustellenden Bildmaterial kann man ein paar Typen unterscheiden:
| Typ | Anzahl | Inhalt | Formate |
|---|---|---|---|
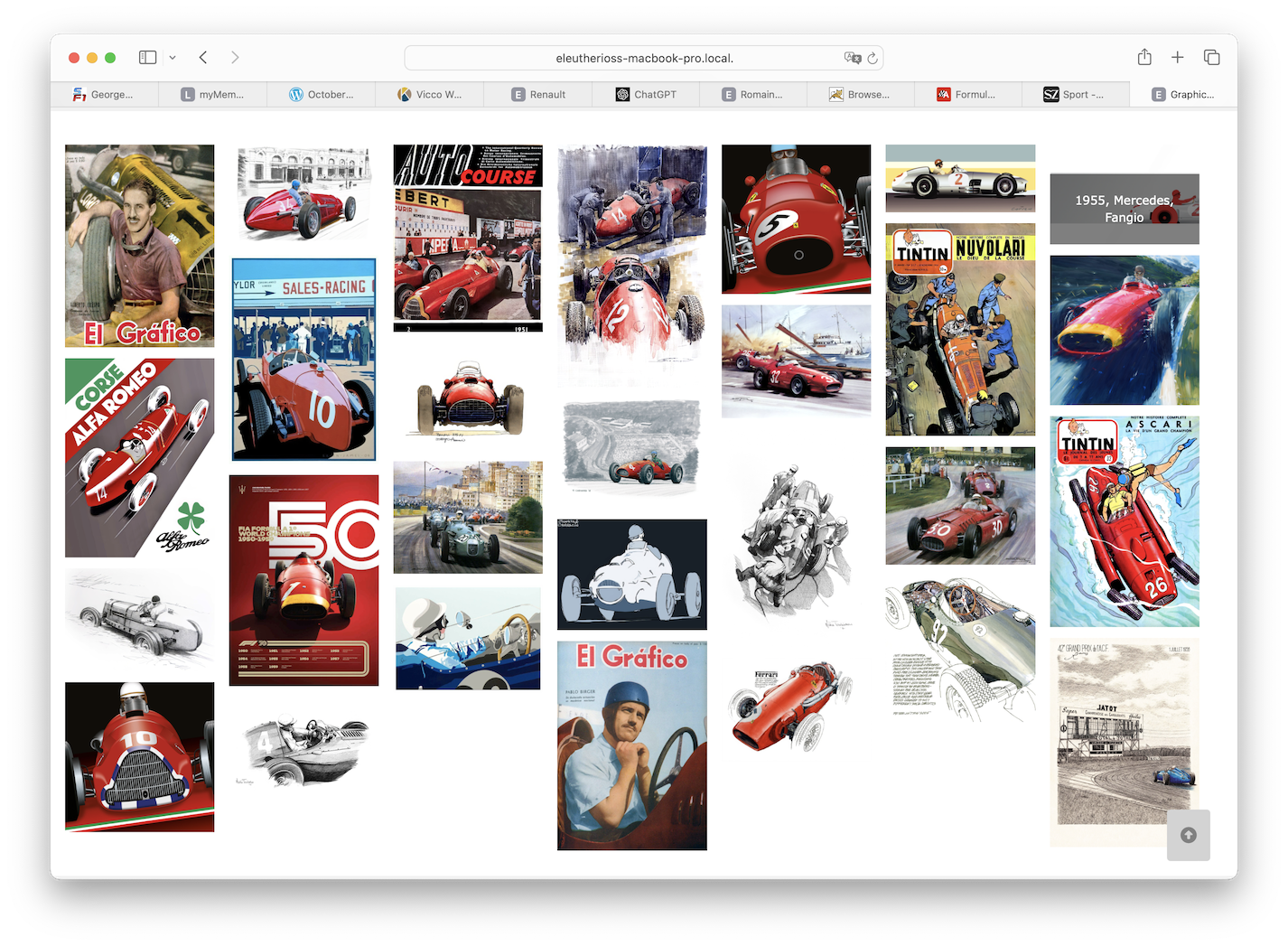
| Photos | ca. 67.000 | Autos, Mechanikern, Designer, Teammitglieder, dem Rennen als Event | Hochformat bzw. überwiegend Querformat, meist ca. 2:3 |
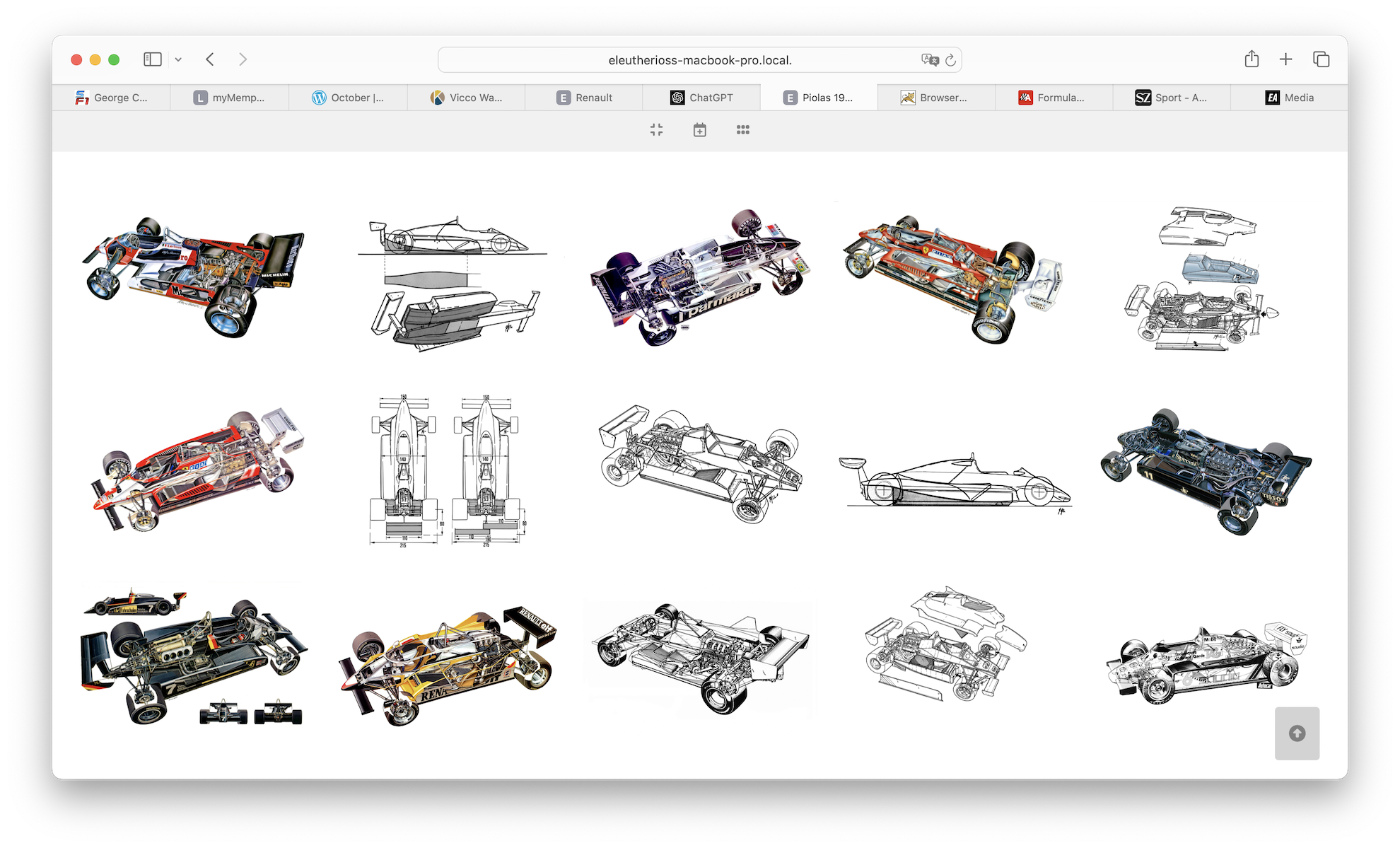
| Cutaways | ca. 800 | Technische Aufrisszeichnungen von Fahrzeugen | nur Querformat, überwiegend ca. 2:3 |
| Poster | ca.1680 | die offiziellen Poster der F1-Rennen seit 1950 | Hochformat, überwiegend wie A4 |
| Buhrer Zeichnungen | ca.50 | Illustrationen von W. Buhrer | unterschiedliche, großflächig |
| Graphiken | ca.480 | Bilder, Zeichnungen und Graphiken | unterschiedlichste |
Beim "Browsen" wird eine Menge von Daten in Teilmengen, die auf jeweils einen Bildschirm/Browserseite passen zerlegt, und dargestellt. Die Gesamtheit der Bilder/Dateien/Dateien kann in Teilmengen "durchsucht" bzw. gesichtet werden.. Weiter unten wird darauf näher eingegangen.
Basis Layout: Spalten oder Zeilen?
Nehmen wir an , wir hätten jetzt eine Teilmenge rausgesucht und wollen die jetzt anzeigen. Eine definierte Menge von *.jpg Dateien in einer HTML Seite anzuzeigen, ist relativ schnell gemacht. Im Grunde genommen ist das die Anordnen von w3-cards in Zeilen und Spalten. Bei den ersten Experimenten zeigte sich, das ein Layout von gleich hohen Zeilen und gleich breiten Spalten (wie bei den Autos von Sauro) eher unbefriedigende Ergebnisse liefert. Sauros Graphiken sind alle im Querformat und haben ein ziemlich konstantes Verhältnis von Breite zu Höhe. Bei den Fotos oder sonstigen Graphiken ist das nicht der Fall. Das führt zu Leerräumen und unterschiedliche Abständen in der Anordnung - ein unbefriedigener Anblick. Um diese Leerräume zu vermeiden blieben bei einem tabellarischen Basis-Layout (Zeilen x Spalten) zwei Varianten:| Entweder sind die Zeilen gleich hoch | oder die Spalten gleich breit |
 |  |
Auch pinterest und andere Dienste hatten diese Entscheidung zu treffen. Ich hab mich bei Bilder mit farbigen Hintergrund für gleich breite Spalten entschieden, und damit für eine etwas un-natürliche "Reihenfolge", da der (westlich geprägte) Mensch von links nach rechts "liest" und auch schaut. Bei gleich hohen Zeilen, sind die Unterschiede bei den Bildformaten auffälliger, sie lassen in jeder Postion Räume frei. Das ist ok, wenn es "Cutaways" mit weissem Hintergrund sind, aber es ist in meinen Augen sehr unruhig bei farbigen Hintergründen.
Ein ebenfalls unbefriedigender Anblick ergibt sich wenn die Länge der Spalten variiert. Das kann duch hochformatige Bilder hervorgerufenwerden, oder wenn die Anzahl der Bilder nicht in das Tabellenraster passt. Pinterest löst das Problem auf simple Weise - es fängt einfach an neue Bilder darzustellen, oder sich zu wiederholen, dadurch kommt man nie an das Ende der Seite. Als Teil der Aufmerksamkeitsökonomie will pinterest ja gar nicht das man aufhört zu scrollen.
Die Länge der Spalten wegen einer unterschiedliche Anzahl/Höhe von Bildern je Spalte halbwegs auzutarieren erfordert, das man die Bilder vor der Darstellung "ausmisst" und dann ein Layout berechnet. Das habe ich programmiert, aber der Aufbau einer Seite dauert dann einfach zu lange. Alternativ könnte man die Daten in den Namen packen oder alle Bilddaten in einer DB halten, aber hier war dann jetzt erstmal "Schluß" für mich - ich mach das ja alles zum Spass und nicht aus Profession.
Layout: Auto Layout oder einstellbares Grid?
Auf einer Seite können beliebig viele Bilder in einem tabellarischen Raster (=Grid) angeordnet werden. Es kann sein das man zu einem Ordnungskriterium nur 1 Bild hat, es kann sein das es mehrere Hundert sind. Wie viele Bild-Dateien will man auf einer Seite darstellen? Will man ein Auto-Layout, sprich die Anzahl Spalten und Zeilen optimal ausrechnen? Oder will man ein statisches festes Schema? Oder will man das Grid frei parametrisieren können und auch den Nutzer einstellen lassen? Welche Größe jedes einzelnen Bildes ist notwendig?
Tja, it depends, wie man so schön sagt ...
Da ich ja hier mein einziger Nutzer und Kunde bin habe ich das für mich für ein klares "sowohl als auch" und "von allem ein bisschen" entschieden.- das Grid ist beim Aufruf einer jsp Seite parametrisierbar
- das Grid ist auch auf der Seite über ein PopUp Menü einstellbar.
- ist die Anzahl der darzustellenden Bilder kleiner als die eingestellte Anzahl der Spalten des Grids, wird das Grid auf die Anzahl der Bilder angepast, so dass immer mind. eine Reihe von Bildern zu sehen ist
- ist die Anzahl der darzstellenden Bilder größer als die durch das Grid gegeben maximale Anzahl auf einer Seite, so kann zu einer weiteren Seite mit der nächsten Menge an Bilder (ebenfalls in dem vorgegeben Grid) verzweigt werden, solange bis alle Bilder dargestelt wurden. Dieses Durchlaufen geht vorwärts und rückwärts.
 |  |
| Bilder passen auf eine Seite | Bilder brauchen mehrere Seiten |
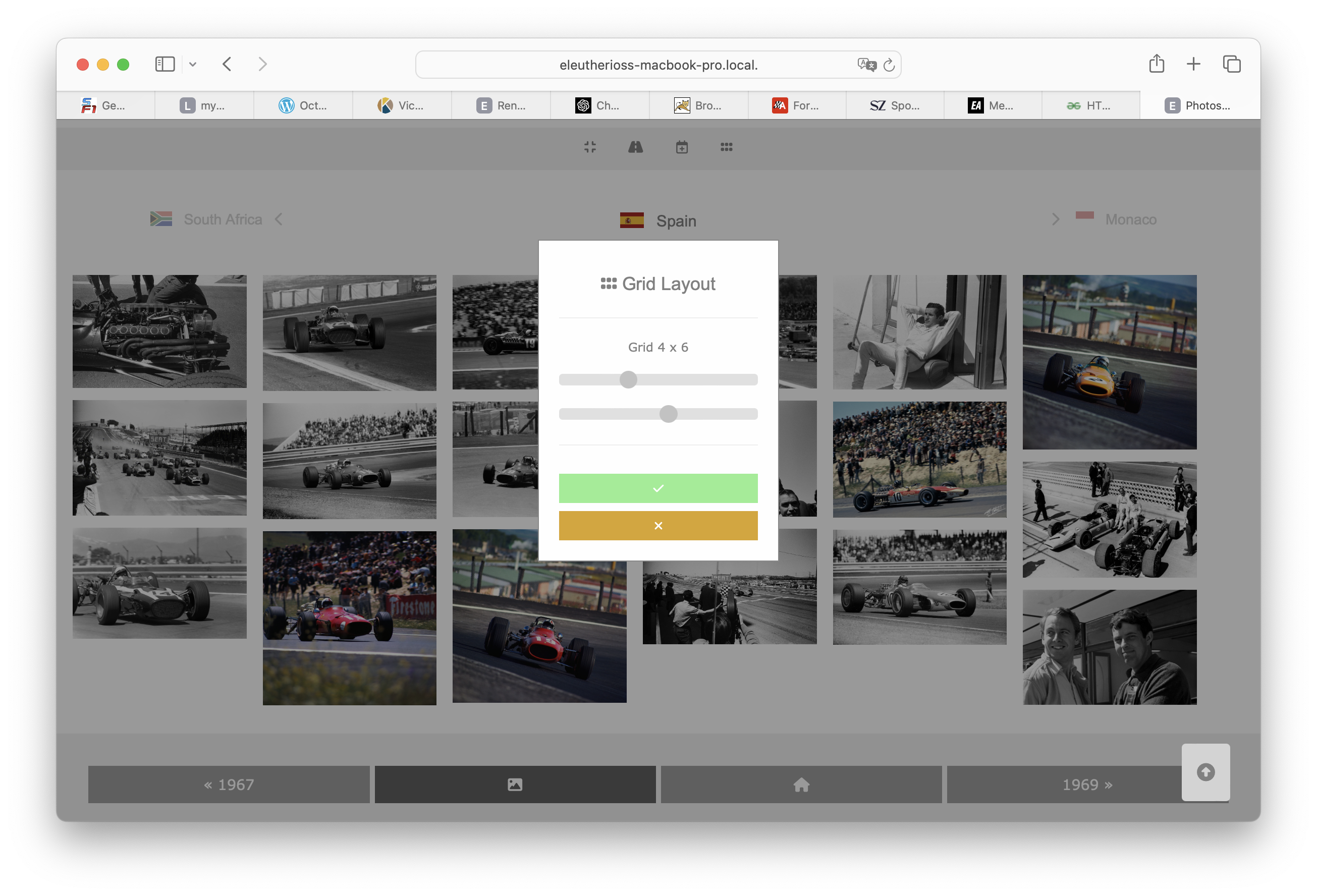
Das PopUp um das Grid anzupassen wird in der zentralen Menuleiste durch ein Icon symbolisiert und wird per Klick aufgerufen.

Es arbeitet mit Schiebereglern - so kann man die Werte schön begrenzen:
Zerlegung: Physik oder Logik?
Beim "Browsen" wird eine Menge von Daten in Einheiten, die auf einen Bildschirm/Browserseite passt zerlegt, und dann wird jede Teilmenge "durchlaufen". Die Kriterien nach denen die Gesamtmenge zerlegt wird, sind das fachlich relevante.Für meinen Foto bzw. jpg Dateien Browser schälten sich im Lauf des Winter 2023/2024 zwei "Use-Cases" heraus:
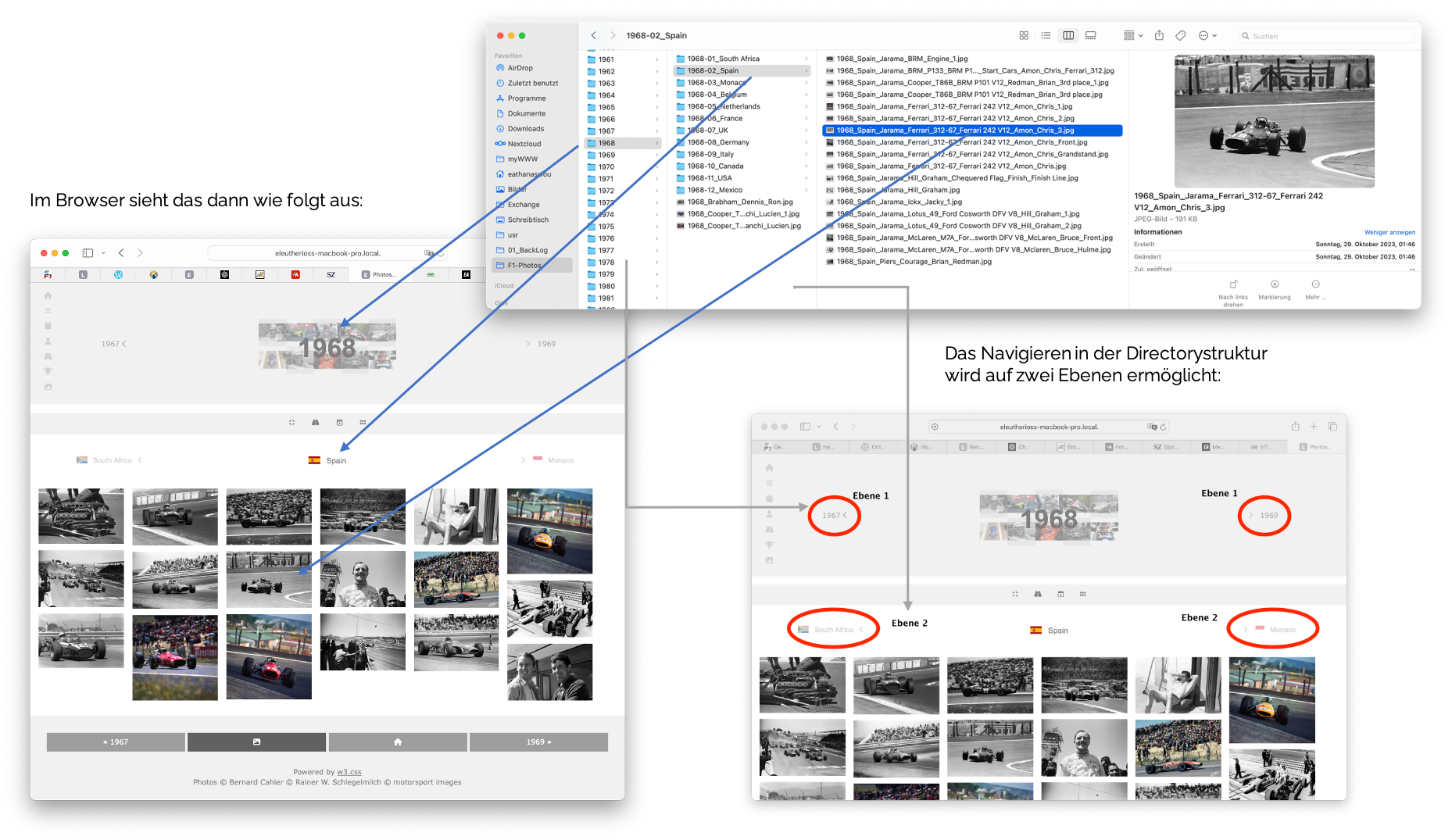
- das "physikalische" Browsen durch auf einem Filesystem organisierten Bild-Dateien
- Das sind zum einen Photos, die im Fileystem nach Jahren und Rennen abgelegt sind, aber auch die Poster (nach Jahren), Cutaways (nach Jahren) und Graphiken (nach Jahrzenten). Es gibt bei den Rennen also 2 Ebenen, und sonst nur eine.
- das "logische" Browsen durch eine "logische" Ebene von Bild. Dateien (die auf einem Filesystem an unterschiedlichsten Directories lokalisiert sind).
- Das kann z.Bsp. das alphabetische Browsen durch die Fahrer sein, oder nach Fahrzeugen je Rennstall, oder was auch immer. Diese "logische" Auswahl wird über eine Query an Lucene realisiert, und dann braucht es kontextspezifische Menüs und Schaltflächen zum weiterbrowsen.
Bei den Cutaways stellt sich das etwas einfacher, weil nur auf einer Ebene dar:
Das "logische" Browsen , sprich Navigieren nach einem "logischen" Ordnungskriterum sieht ziemlich gleich aus - die Navigationsebene ist halt nicht "physikalisch":
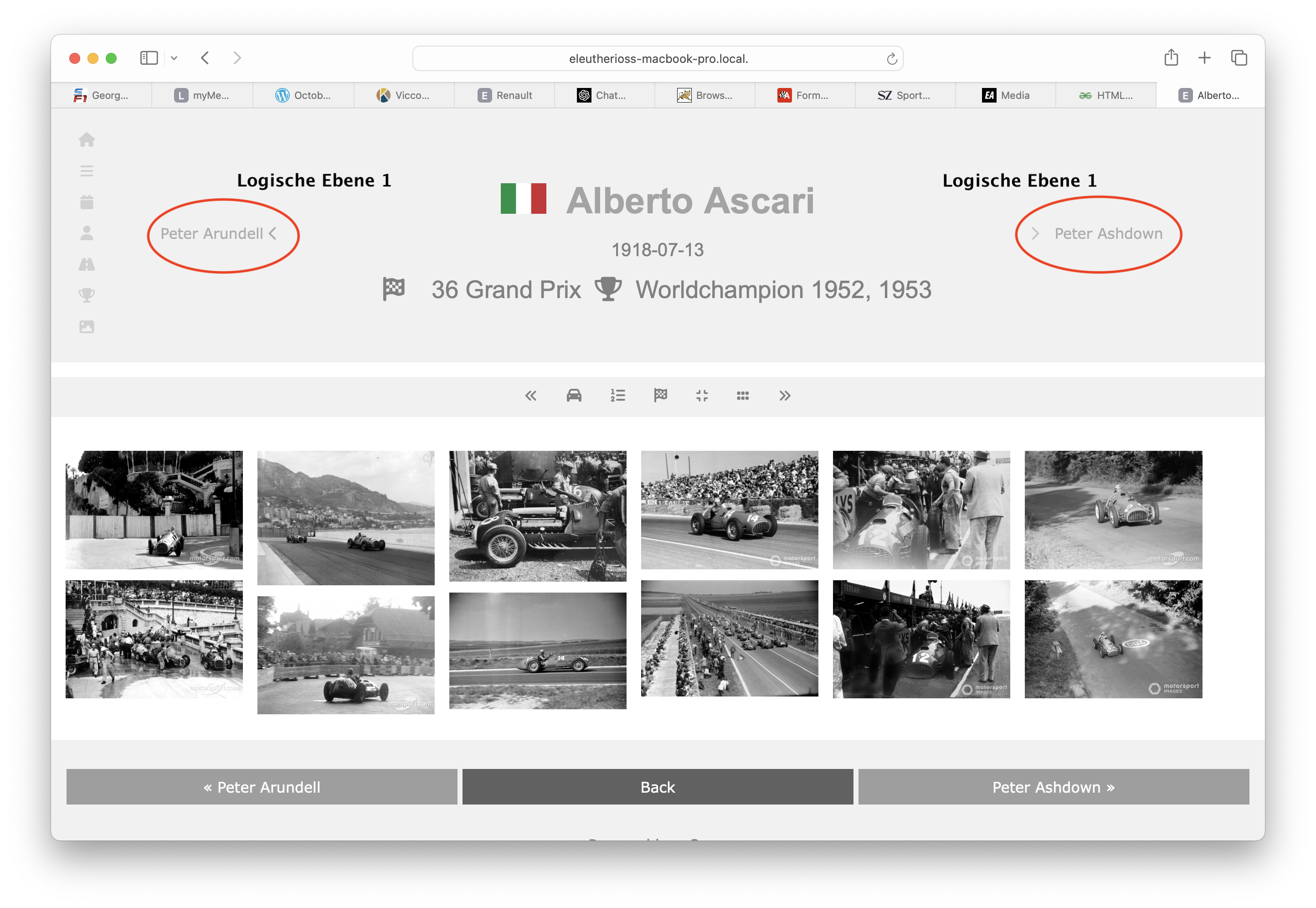
Beim "logischen" Browsen kann ich mir auch eine zweite Ebene vorstellen, es wäre ein zweite Ordnungskriterum innerhalb einer Query. Bspw. alle Fotos eines Teams (Ebene 1) nach Jahren (Ebene 2). Für irgendetwas muss die ganz Taggerei ja gut sein ...